Description
 Automatically extract handwriting, text or data from any document using machine learning
Automatically extract handwriting, text or data from any document using machine learning
Amazon Textract is a service that automatically detects and extracts text and data from scanned documents. It goes beyond simple optical character recognition (OCR) to also identify the contents of fields in forms and information stored in tables
Benefits
- Extract data quickly and accurately
Amazon Textract makes it easy to quickly and accurately extract data from documents and forms. Amazon Textract automatically detects a document’s layout and the key elements on the page, understands the data relationships in any embedded forms or tables, and extracts everything with its context intact. This means you can instantly use the extracted data in an application or store it in a database without a lot of complicated code in between
- No code or templates to maintain
With Amazon Textract’s pre-trained machine learning models, you don’t need to write code for data extraction. This is because the models have already been trained on tens of millions of documents from many industries—including invoices, receipts, contracts, tax documents, sales orders, enrollment forms, benefit applications, insurance claims, and policy documents. You no longer need to maintain code for every document or form you might receive, or worry about how page layouts change over time.
- Easily implement human reviews
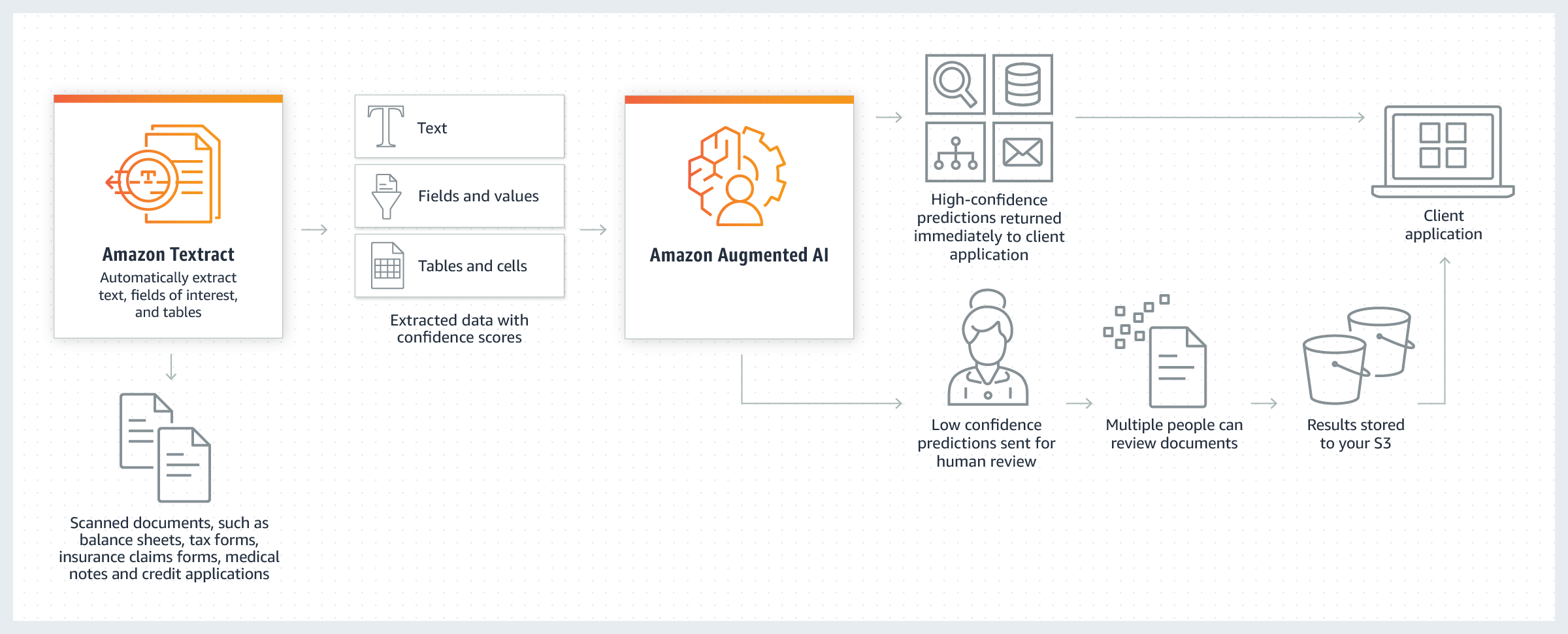
With the addition of Amazon Augmented AI you can build-in human reviews to manage nuanced or sensitive workflows that require human judgement to get high confidence predictions or to audit predictions on an on-going basis.
- Lower document processing costs
Amazon Textract’s text extraction API enables you to process documents for $1.50 per 1,000 pages. Whether you process a few hundred documents a year or millions, Amazon Textract provides OCR and structured data extraction (forms and tables) at a very low cost, and you only pay for what you use. There are no upfront commitments or long-term contracts.
How it works
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from scanned documents. It goes beyond simple optical character recognition (OCR) to identify, understand, and extract data from forms and tables. Today, many companies manually extract data from scanned documents such as PDFs, images, tables, and forms, or through simple OCR software that requires manual configuration (which often must be updated when the form changes). To overcome these manual and expensive processes, Textract uses ML to read and process any type of document, accurately extracting text, handwriting, tables, and other data with no manual effort. You can quickly automate document processing and act on the information extracted, whether you’re automating loans processing or extracting information from invoices and receipts. Textract can extract the data in minutes instead of hours or days. Additionally, you can add human reviews with Amazon Augmented AI to provide oversight of your models and check sensitive data.
Features
- Key-value pair extraction
Amazon Textract enables you to detect key-value pairs in document images automatically so that you can retain the inherent context of the document without any manual intervention. This makes it easy to import the extracted data into a database, or to provide it as a variable into an application.
- Table extraction
Amazon Textract preserves the composition of data stored in tables during extraction. This is helpful for documents that are largely composed of structured data, such as financial reports or medical records that have column names in the top row of the table followed by rows of individual entries
- Handwriting Recognition
Many documents such as medical intake forms or employment applications contain both handwritten and printed text. Amazon Textract can extract printed text and handwriting from documents written in English with high confidence scores, whether it is free-form text or text embedded in tables and forms. Documents can also contain a mix of typed text or handwritten text.
- Invoices and Receipts
Amazon Textract can extract relevant data such as contact information, items purchased, and vendor name, from almost any invoice or receipt without the need for any templates or configuration. Invoices and receipts come in various layouts which makes it difficult and time consuming to manually extract data at scale. Amazon Textract uses ML to understand the context of invoices and receipts and automatically extracts data such as vendor name, invoice number, item prices, total amount, and payment terms, which are useful for customers.
- Identity documents
Amazon Textract uses ML to understand the context of identity documents such as U.S. passports and driver’s licenses without the need for templates or configuration. You can automatically extract specific information such as date of expiry and date of birth, as well as intelligently identify and extract implied information such as name and address.
- Bounding boxes
All extracted data is returned with bounding box coordinates. The coordinates make up a polygon frame that encompasses each piece of identified data, such as a single word, a line, or a table. This is helpful for being able to audit where a word or number came from in the source document. It also helps to guide the user in document search systems that return scans of original documents as the search result.
- Confidence scores
When information is extracted from documents, Amazon Textract returns a confidence score for everything it identifies so that you can make an informed decision about how you want to use the results.
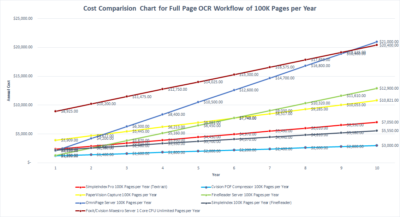
Amazon Textract pricing
Amazon Textract is a machine learning (ML) service that uses optical character recognition (OCR) to automatically extract text, handwriting, and data from scanned documents such as PDFs. With Amazon Textract, you pay only for what you use. There are no minimum fees and no upfront commitments. Amazon Textract charges only for pages processed whether you extract text, text with tables, and/or form data. You can get more details here.